The Blackwell goes up to ~750mm2 it is a completely different beast. And Nvidia is already having trouble trying to fill up their Blackwell on a higher capacity, relatively mature N4 Node. Imagine doing it on an expensive N3, and then charge $4999 only to get outrage as rip off on HN and reddit.
Generally speaking the larger die size, high performance chip tends to be a node behind simply because all the leading edge node and tools aren't even designed for them but are specifically aiming at Mobile SoC. Then you add in cost issue and yield.
And you cannot look at the number of SKUs without also taking into account how many different die designs are being manufactured and binned to produce that product line. Intel and AMD CPUs have far more bins per die, and usually fewer different die sizes as a starting point. Apple isn't manufacturing a M3 Max and sometimes binning that down to a M3 Pro, or a M3 Pro down to a M3. You're really just seeing about two choices for enabled core count from each die, which is not any kind of red flag.
Back when Intel was stagnant at 4 cores for the bulk of their consumer CPU product line, they did stuff like sell i7 parts with 8MB L3 cache and i5 parts with 6MB cache, more as a product segmentation strategy than to improve yields (they once infamously sold a CPU with 3MB last level cache and later offered a software update to increase it to 4MB, meaning all chips of that model had passed binning for 4MB). Nowadays Intel's cache capacities are pretty well correlated with the number of enabled cores. AMD usually doesn't vary L3 cache sizes even between parts with a different number of enabled cores: you get 32MB per 8-core chiplet, whether you have 8 cores or 6 cores enabled.
I don't know to what extent the cache sizes on Apple's chips vary between bins, but it probably follows the pattern of losing only cache that's tied to some other structure that gets disabled.
Of course, even if N3B is fine for desktop CPUs and for smaller GPUs, it may still have too low yields for chips of the size of the top models of NVIDIA GPUs.
https://semianalysis.com/2022/07/24/the-dark-side-of-the-sem...
10x is cool but when that's still catching up it's not done.
>[Arguing about instruction sets] is a very sad story. It's not even a couple of dozen [op-codes] - 80% of core execution is only six instructions - you know, load, store, add, subtract, compare and branch. With those you have pretty much covered it. If you're writing in Perl or something, maybe call and return are more important than compare and branch. But instruction sets only matter a little bit - you can lose 10%, or 20%, [of performance] because you're missing instructions.[0]
I've cited this article a few times already (and seen others cite it) so if this is incorrect I hope someone could correct me here. (I have to assume that you also need some sort of SIMD/Vector these days, which RVA23 has anyway, but aside from that.)
I've also read that you can port CPU cores to a different ISAs pretty easily which is what PA Semi did when Apple bought them (M1 devs). So what seems to be missing is for a bunch of senior CPU developers who worked at AMD, Intel, PA Semi/Apple or ARM to just make one for RISC-V. Not sure if that is what you meant by IP here. Tenstorrent could be one such group, and they are building RISC-V CPUs, but their focus seems to be split between that and AI accelerators. China is another good candidate.
[0] https://www.anandtech.com/show/16762/an-anandtech-interview-...
> Not sure if that is what you meant by IP here.
By IP I meant intellectual property. I was wondering how much designs or specific hardware developments that were essential for the performance boost (or: energy efficiency of chips, compute/W) as observed with the Apple M family of designs are locked down by patents.
But the larger value is that then people could use it as a starting point for modifications, which would in turn have to be released under the same license. Soon you have a diverse set of designs to choose from and we can start getting open hardware into common use because using any of those designs would be a cost savings over buying or designing something equivalent, but because the license requires an open design the user can then create custom firmware etc. and we might finally start to do something about the IoT security nightmare.
Like the CERN Open Hardware License?
Will RISC-V get there eventually? People like Jim Keller are building companies around that goal. However, it will likely take years, at least, for RISC-V to approach parity.
Unless modern civilization ends or an easier alternative is released eventually anything Open Source will get good enough.
https://semianalysis.com/2022/07/24/the-dark-side-of-the-sem...
Sigh. So basically we assume this is all aspirational spin and that either they haven't finalized the parameters for the process yet or they know the numbers will be disappointing already.
The era of VLSI scaling is over for sure. Hilarious that Intel's complete failure at process development happened at exactly the moment where it could do the least damage.
I'm not sure that we can say that. They may be keeping their cards close to their chest for any number of reasons. Unless they think they also had "bad" numbers in the past several years when they were doing the same thing.
TSMC publishes industrial research, not pure science research like a university.
In this context the amount of detail they release is careful balance of PR benefit vs. competitive advantage vs. patent status vs. keeping their talent happy because good researches want their names in prestigious journals.
It's interesting how the whole valuation of TSMC(and some from NVidia) are aligned by their current advantage on the 3nm process.
Intel on 18A is literally TSMC's 3nm process + backside power delivery, which means more power efficiency, performance also less heat.
It's definitely what they need to get them back into the processor game and beat everybody, maybe we will see Apple doing designs with the Intel factory before 2030?
Hope they don't fail their deadlines: summer this year to be producing 18A, and 2026 mass production.
That's a pretty serious abuse of the word "literally" given that they have nothing in common except vague density figures which don't mean that much at this point.
Here's a line literally from the article
>Based on this analysis it is our belief that Intel 18A has the highest performance for a 2nm class process with TSMC in second place and Samsung in third place.
Given what we currently know about 18A, Intel's process appears to be less dense but with a higher emphasis on performance, which is in line with recent Intel history. Just looking at the density of a process won't tell you everything about it. If density were everything then Intel's 14nm++++ chips wouldn't have managed to remain competitive in raw performance for so many years against significantly denser processes. Chip makers have a bunch of parameters they have to balance when designing new nodes. This has only gotten more important as node shrinks have become more difficult. TSMC has always leaned more towards power efficiency, largely because their rise to dominance was driven by mobile focused chips. Intel's processes have always prioritized performance more as more of their products are plugged into the wall. Ideally, you want both but R&D resources are not unlimited.
You make somewhat more power efficient chips, you get to sell it for a lot more.
Your chips are inefficient, and you won’t be able to sell to a hyperscaler even for $0.
The latter is the position Intel is quickly arriving at for DC; Epycs are much more efficient and Intel’s wildly slashing prices.
—
For Apple, A-series dies are pretty small, they basically prefund a large part of TSMC and almost certainly gets the lowest prices of any customer.
That said, Apple’s strict fascination with always jumping to the latest node, even when it seems premature, puzzles me from the outside.
As a user of M1, M2 and M4, that's why I've chose Apple.
I would have gladly jumped to any laptop that supports Linux with similar power and battery life and weight/build, unfortunately that computer does not exist.
Is it time to call on garmin to make a computer? They've beat apple on the watch. I have faith in them.
Just saw this podcast: https://www.youtube.com/watch?v=hvQvrLjlJN8
CEO of ASML, he sees a path for the next 5-15 years for a 2 year cadence of transistor scale doubling. That's a bit slower than 18 months, which it was earlier.
Fabs consume enormous quantities of water and Arizona (and the sw) are already in precarious position, and not even a semi viable theoretical option like desalination possible in the future
A sweeping statement, like plastic is recycled. It is more complex than that.
It is energy intensive (and expensive) to recycle both low purity and ultra pure water (UPW) used and for some fabs it is just 40% [1] and there is no consistent globally adopted solution, most of the tech used is still evolving and not implemented everywhere.
It’s exaggerated, but it still represents some degree of progress.
Intel invented a new number they can count down. Do we already know what naming scheme TSMC will adopt for the next generations?
Weird.
Intel says that 18A will be a thing around mid of 2025, so 4-6 months from now, I think.
Then it will upgrade to HVM between Q3 and Q1 iirc
According to what Intel claims, it will be launched in H2 2025, i.e. with commercial availability either in October or in December, depending on how quickly Intel will succeed to improve the yields of the 18A process.
> In terms of the overreaching Power, Performance, and Area (PPA), the paper states that the process delivers a 30% power improvement or 15% performance gain and >1.15x density versus the previous 3nm node.
Since I know the nm numbers are meaningless anymore, it’s kind of an insult to the math of 3 to 2 to call these sorts of minor improvements that.
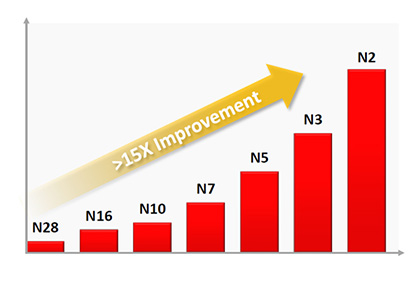
<https://semiwiki.com/wp-content/uploads/2025/02/Figure-1.jpg>
You see, the bars go up and to the right as indicated by the arrow. The thing at the top right, which is under discussion, is more than fifteen times better than the thing on the bottom left.
This is a huge achievement.
> We took the graph image, pulled it into Excel and created an Excel graph overlaying it with the 28nm bar normalized to 1 and then entering values for the other bars until they matched the graph. If we then build a set of bars starting at 28nm = 1 scaled up based on the TSMC announced node to node power improvements we get a total improvement of less than 9x. Nodes from N28 to N10 match well but from N7 on the bars on the graph show more improvement per node than TSMC has announced. Just the N3 to N2 bars on the graph show a 55% improvements versus the announced 30% improvement.
> …
> It isn’t clear what may be driving this difference, but it is a big disconnect. This may be why the graph was removed from the final paper.
It shouldn't limit innovation and trying to go past those limits one way or another, but at some point it feels like marginal (or below expectations) progress isn't acceptable at least for a while. That it then has to become coated in some marketing lie or half-truths to mask reality and oversell what it truly is... That's still progress! And it can slow down, accelerate, who knows? This should be acceptable.
Please, please Raspberry Pi, also make a 2nm version
Actually, I think it's broadcom I need to ask that from isn't it ?
(Although then I think it would almost become a Jetson)
Please please NVidia make a 1nm Jetson, the planet needs you to.
So, far off needing a bleeding edge node[2] to see further improvements.
[1]: https://chipwise.tech/our-portfolio/raspberry-pi-5/
[2]: https://www.tsmc.com/english/dedicatedFoundry/technology/log...
Having said that. The Jetson runs at around 7W doing that and a lot faster inference. Just a lot more expense. Likely the Jetson will eventually be something like 2nm. So maybe we see around 4W at that time running an object detector. And of course the Jetson has the memory and processor together on it's modules so everything can benefit. Just dropping the power on the Pi for the processor leaves that out.
But thanks for the links
Just goes to show manufacturing node isn't everything. There's a lot of various optimizations one can do depending on targets.
Guess we'll just have to see what the future brings.
{kind=link}